




近年来,大型语言模型(Large Language Models,以下简称为LLMs)与人工智能(AI)的快速发展,更新了全球技术创新的进程。LLMs通过海量数据的预训练,捕捉文本、图像、语音、视频等的深层关联模式,实现灵活生成与推理,为AI系统提供高效的信息处理支持,在多种领域已展现出显著的效率提升和应用创新潜力。
然而,LLMs依赖海量数据训练和复杂算法驱动的特性,也引发了关于数据隐私、伦理责任与合规边界的激烈争议。德国作为欧盟数据治理的重要国家,其国内不同州数据保护监管机构对LLMs与AI的态度分歧,直接影响了针对个人信息保护法定义务范围的界定,成为观察AI治理范式的关键样本。
2024年12月,欧洲数据保护委员会(EDPB)针对AI模型处理个人数据问题发表了意见,其核心立场是要求在AI模型开发全流程中做好数据保护工作,通过“匿名化”等技术措施减少合规风险,同时再次区分AI模型开发阶段和部署阶段来明确责任归属[1]。然而,作为部分AI系统重要组件的LLMs在处理个人数据时应遵循的规则,并未在EDPB的官方意见中得到特别关注。我们希望通过对德国监管机构的意见分析,进而把握欧盟及其成员国在AI与LLMs关系问题上的监管预期,为企业合规实践提供建议。
一、问题与背景
德国数据保护框架以欧盟《通用数据保护条例》(GDPR)和《联邦数据保护法》为核心,强调个人数据的“目的限制”、“最小化原则”与“透明性要求”。然而,LLMs的“黑箱”特质与数据处理模式,直接挑战了传统的合规逻辑。LLMs的自主生成机制与法律预期的“可预见性”、“因果关系”等归责原则明显无法衔接。当模型基于海量跨领域数据与复杂参数权重生成包含偏见、错误甚至侵权的文本、图像、语音、视频等时,既无法追溯其与特定训练数据的直接关联,也难以划分开发者、部署方与用户的责任边界。在个人信息保护方面,模型的预训练(pre-training)数据可能包含未经明确授权的个人数据,而生成内容的不可预测性则增加了满足透明度要求的难度,相应数据合规的责任归属模糊性加大,法律调整的规则难度提高。
EDPB目前尚未对“LLMs处理个人数据是否属于GDPR的管辖范围”的问题发表意见。德国汉堡州数据保护机构、巴登-符腾堡州数据保护机构对LLMs处理个人数据问题提出了不同的立场。汉堡州数据保护机构通过研究[2]得出结论:本地化存储LLMs本身不构成个人数据处理[3]。巴登-符腾堡州数据保护机构则提出截然不同的观点,认为应将LLMs和AI系统作为一个整体去看,系统评估个人数据泄露的风险[4]。可以看出,既使在同一国家,由于对模型算法和数据应用的过程理解不同,监管机构对治理路径选择的意见也有很大差别。
LLMs、AI系统的开发者和部署者都应密切关注相关认定标准的政策趋势,谨慎选择实践工作中的合规方案,防止应用架构因后期合规的原因发生大幅调整而产生资源浪费。
二、LLMs与数据泄露风险
(一)LLMs简介
大语言模型(LLMs)是基于Transformer架构[5]构建的复杂机器学习系统,其核心特征在于通过万亿级甚至数十万亿参数构成的分布式组件,实现对人类语言模式的大规模学习与生成。
(二)LLMs如何收集数据
针对AI系统应用LLMs的场景,德国联邦数据保护监督系统(BfDI)对二者的关系进行了梳理,通过其技术数据保护国际工作组[6]发布了工作论文[7],详细讨论了LLMs作为AI系统核心组件的角色,从工作原理的角度拆解个人数据在LLMs训练数据时泄露风险的路径。该工作组概括了LLM的三个工作阶段:预训练(Pre-training)、微调与对齐阶段(Fine-tuning / alignment)和使用(Use),详见图1。
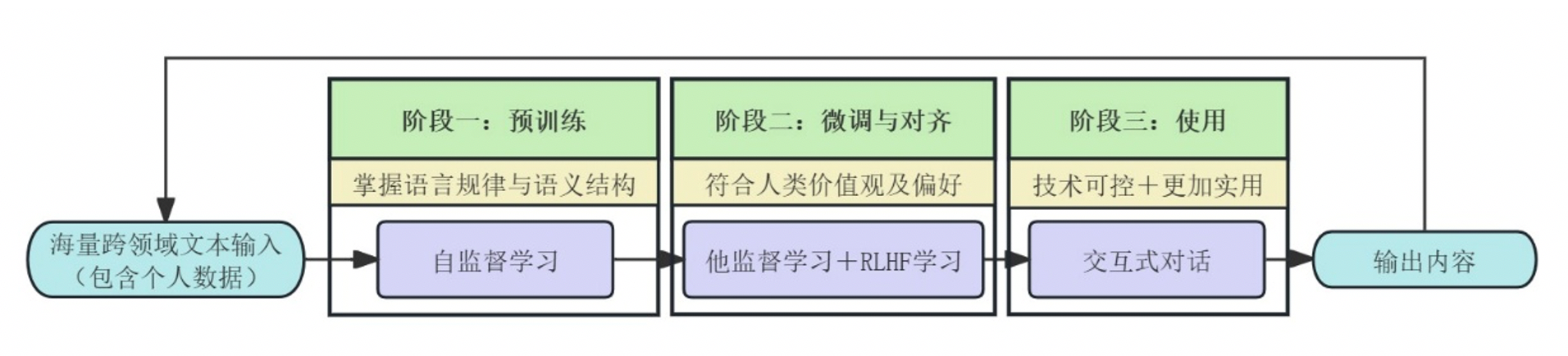
图1 LLM工作阶段
-
预训练阶段:是通过自监督学习(self-supervised training)创建一个通用“基础模型(foundation model)”[8]的过程,使模型从海量无标注文本、图像、语音、视频等中掌握语言的统计规律与潜在语义结构。该方法以跨领域数据为原料,通过去重、隐私过滤和质量分类实现数据清洗,剔除冗余、敏感及低质量内容。训练时,模型基于输入序列进行下一个词的预测任务,借助Transformer架构的上下文建模能力,通过不断优化参数以减少预测误差,最终形成对词汇分布、句法规则及语义关联的,为下游任务提供可迁移的“基础模型”。在模型稳定性不足或存在安全漏洞时,个人数据尤其是个人身份信息容易通过模型意外泄露。
-
微调与对齐阶段:通过引入符合人类偏好和人类价值观、将“基础模型”转化为符合“3H原则”( helpful, honest and harmless)[9]的可靠系统。在该过程的“他监督学习(supervised learning)”阶段,模型通过人工标注的高质量指令训练完成从文本续写转向指令遵循的学习,优化语言响应能力;在后期的“基于人类反馈的强化学习”阶段通过阶梯式流程,实现语言模型伦理决策能力的优化,动态平衡“3H原则”,优化模型输出的准确性和安全性。由于人类评估者本身可能存在偏见或容易做出错误决策,且AI会进一步强化评估者的非伦理倾向,这种情况下形成的“AI幻觉”可能对用户个人产生极大危害性且难以察觉,并加剧数据滥用及泄露风险。
- 使用阶段:表现为基于提示(Prompts)[10]与温度参数(Temperature)[11]的交互式问答系统。该阶段以用户输入的提示词为核心驱动,通过指令、上下文、输入数据、输出指示及示例等结构化元素引导模型生成特定任务响应。其运作过程即“提示”首先被拆分为语义单元(Token),由Transformer架构的注意力机制解析词汇关联与意图,依托训练所得的权重参数,逐个Token预测并生成连贯文本。然而,该生成过程可能受限于训练数据的内在偏差或概率采样策略,导致输出内容出现事实性错误。开发者通过调整温度系数,可在概率分布的随机抽样与确定性筛选之间建立平衡机制,从而更好地控制大语言模型随机性和确定性的平衡。在此过程中存在海量个人数据需要匿名化,故很可能存在匿名化不足而导致信息泄露的风险,还包含提示词可能引发的滥用风险。
(三)LLMs如何泄露数据
许多大模型开发者认为,参与训练的数据越多,系统就能“学习”越多,输出也就越复杂、越精确。AI行业鼓励无限制的大规模数据收集[12]。可是这与GDPR的隐私保护原则以及数据最小化等原则直接冲突。为了满足这种对大规模数据的需求,许多开发者建立系统,不加区别、持续地从互联网上抓取数据。这就使得数据的质量无法得到保障,其中那些不准确、有偏差、有歧视性的信息直接产生数据治理合规的问题。
三、德国数据保护机构对AI与LLMs存储数据的不同意见
(一)汉堡州数据保护机构:存储LLMs本身不构成个人数据处理[13]
汉堡州数据保护机构2024年发布了一篇政策讨论文章,深入解释了LLMs不存储个人数据的原因,反映了汉堡州关于LLMs与数据保护问题的最新研究成果。虽然该文章没有强制性效力,但其表达的观点反映了该州数据治理和监管的政策倾向。
1. LLMs不存储个人数据,因此LLMs与GDPR规定的数据主体权利无关
LLM作为AI系统的组件,仅仅存储LLMs并不构成GDPR第4(2)条[14]意义上的数据处理。这是因为LLMs中不存储个人数据。但LLMs被嵌入至实际运行的AI系统中并参与处理个人数据时,整个AI系统的运行过程则必须严格遵守GDPR确立的数据保护原则。
从法律层面看,GDPR要求个人数据必须“与已识别或可识别的自然人相关”,而LLMs的嵌入向量和参数仅反映语言结构,缺乏与特定个体的直接关联性。正如欧盟法院判例中的IP地址、借书卡号等只是“标识符”,这种关联源于他们的标识符功能与其包含的信息,需借助外部数据库才能关联到人,但LLMs内部不存在此类可溯源的标识体系。即便通过高成本的隐私攻击复现了训练片段,此类手段因需突破技术保护措施且依赖未公开的训练数据比对,既不符合GDPR“合法且不成比例努力”的识别标准[15],也可能构成法律禁止的行为,因此无法证明LLMs本身存储了个人数据。
由于LLMs中不存储个人数据,GDPR所定义的数据主体权利与模型本身无关。
2. LLMs训练阶段潜在违规行为不直接影响其在AI系统的使用
即使不在AI系统中使用,训练LLMs也可能会使用个人数据,训练过程必须符合数据保护的要求。但是,训练阶段的违规不应影响已训练完成的模型在AI系统中的合法使用。LLMs训练数据期间的违规行为不应归咎于后期应用过程的部署者。
从技术层面,LLMs通过分词技术(tokenization)和嵌入技术(embeddings)将包含个人数据的文本、图像、语音、视频等转化为数学向量,仅记录语义结构的概率关系,而非原始数据或可识别的个人信息。这种抽象数学关联无法逆向还原出具体内容。例如模型可能学习“姓名与常用地址关联”的模式,却不会存储“张三住某某区”的真实数据。既然LLMs本身不存储个人数据,那么GDPR就无法直接约束LLMS对数据处理的相关操作。
同时,根据GDPR的监管框架,训练与部署阶段的责任主体分离,各负其责,且部署者在使用阶段可以通过输入过滤、封闭式系统设计及动态合规措施主动隔离风险。因此,监管机构应更关注实时数据处理对用户的实际影响,而非历史训练缺陷。LLMs训练阶段潜在违规行为不直接影响其在AI系统的使用。
综上所示,德国汉堡州数据保护机构做出以下合规提示:
对开发者的要求:开发者需在训练阶段遵守GDPR,优先使用合成数据以减少个人数据使用从而履行GDPR第25条的相关原则[16]。若使用个人数据,需确保其数据处理过程符合相关规定并保障数据主体的各项权利。
对部署者和用户的影响:企业在部署第三方开发的LLMs时,无需因训练阶段违规而停止使用,但需确保自身AI系统的输入和输出处理符合GDPR。用户可针对AI系统的输入和输出情况主张相关权利,但无权直接要求开发者修改LLMs本身。
(二)巴登-符腾堡州数据保护机构:要将LLMs和AI系统作为一个整体[17]
巴登-符腾堡州的数据保护机构为了总结最新研究成果,厘清市场主体和监管机构涉及AI开发、监管的法律依据,专门在其官网上发布了一篇政策讨论文章,其中关键内容直接点评了汉堡州数据保护机构关于LLMs与AI系统的相关态度。
该论文从个人关联(personal reference)出发,认为应把LLMs和AI系统视为一个整体。主要原因是个人数据的可识别性不仅取决于模型本身的结构或存储内容,更依赖于整个系统与外部信息、用户的交互。
虽然LLMs在训练后可能未直接存储原始个人数据,但其输入和输出的交互机制可能成为识别自然人的关键桥梁。例如,用户通过特定提示词,如包含姓名、出生日期、地理位置等细节的查询,这可能诱导模型生成与可识别个体相关的真实或虚构信息。此时模型输出的结果与用户输入的上下文结合,便可能构成GDPR意义上的个人数据。
从技术层面上讲,AI系统的技术漏洞如模型反演攻击可能使攻击者通过逆向工程从模型参数中推断出训练数据中的敏感信息。这意味着即使模型未直接存储个人数据,其内在表征仍隐含可识别的信息,即间接存储指向个人数据的信息[18]。因此,只有将模型嵌入到完整的AI应用生态中,才能全面评估模型是否符合数据保护的监管要求。
这种整体分析视角不仅反映了技术复杂性与法律适用性的交织现实,也强调了在动态技术环境中“可识别性”[19]需要结合现有技术发展、用户行为及模型控制能力等方面的因素进行综合判断。
四、两种思路下治理机制的选择和合规路径的分歧
汉堡州和巴登-符腾堡州数据保护机构关于LLMs处理个人数据的分歧,实质上反映了欧洲数据保护体系在数字时代面临的共性挑战——如何在技术不可解释性与法律可归责性之间建立新型平衡机制。
在没有完全建立明确的平衡机制前,我们建议相关企业密切关注不同的政策选择的可能性,以及对企业合规方式和路径的影响,谨慎开展当前的企业合规实践。
1. 考虑构建欧盟及其成员国监管层面的“双重合规”
EDPB虽为欧盟AI治理提供了基本标准,但德国汉堡州与巴登-符腾堡州的分歧表明,企业需要考虑构建“双重合规”的架构:既要满足EDPB对匿名化技术标准的宏观要求,又需针对成员国立法差异设计弹性方案,二者的侧重取决于最终的规则要求和合规细节。同时,企业应积极参与EDPB意见征询,推动相关标准、指南的进一步细化,减少成员国解释空间差异导致的额外合规成本支出。
2. 关注LLMs预训练阶段个人数据的“匿名化”处理、交易价格中恰当评估合规成本
预训练阶段,相关AI企业应采用EDPB认可的匿名化技术,并定期进行数据匿名性检测,做好“正当利益”证明等数据合规评估。涉及AI产品的交易中也应考虑个人数据合规处理可能需要的成本,必要时应将其纳入合同价格的计算和谈判中。在预训练阶段就关注匿名化处理工作,无疑会增加合规成本,但在跨境业务的管理上确实也可以提高公司经营管理的效率,减少为了满足不同监管要求带来的冲突和资源重复占用。
3. 交易过程应厘清主体责任归属、留存基础证据
在相关AI产品的责任范围和归属方面,企业需厘清数据提供方、开发方、部署方的责任划分,通过合同明确相关主体的责任。合同交付和执行过程,包括AI产品的运行过程中,应注意留存技术文档和系统日志,为后期可能在不同司法管辖区发生的产品责任争议和合同纠纷保留基础证据。
4. 合同条款的谈判与确定应关注不断变化的监管要求
涉及AI的商业交易中,应注意各国针对数据保护的差异化要求。合同双方应根据数据泄露等意外情况和风险损害程度划分责任,也可以考虑通过具体条款约定技术合规成本的分担方式。我们建议在欧盟统一规则尚未明确期间,提供LLMs与AI系统产品及服务的企业要正视相关合规挑战,合同条款的谈判和确定应不断关注可能变化的监管要求。
注释:
[1] 详见:王可、孙泽文《环球科技法前沿系列 | 欧洲数据保护委员会明确AI模型与个人数据处理的意见》2025年3月,https://mp.weixin.qq.com/s/MSgXDcr7zupw-IsT7rqE-A
[2] 此篇文章为德国汉堡州数据保护机构的一篇讨论文章:Discussion Paper: Large Language Models and Personal Data,详见https://datenschutz-hamburg.de/fileadmin/user_upload/HmbBfDI/Datenschutz/Informationen/240715_Diskussionspapier_HmbBfDI_KI_Modelle.pdf
[3] 存储LLMs是指将经过训练的大规模语言模型以持久化形式保存至特定存储介质或系统的过程。
[4] 此篇文章为巴登-符腾堡州数据保护机构的一篇讨论文章:Discussion paper :Legal basis in data protection in the use of artificial intelligence,详见https://www.baden-wuerttemberg.datenschutz.de/rechtsgrundlagen-datenschutz-ki/
[5] Transformer是一种用于自然语言处理和其他序列到序列任务的深度学习模型架构。
[6] 即“柏林小组”(Berlin Group),由来自数据保护监管机构、政府机构、国际组织和非政府组织以及研究和学术界的参与者的异质性跨国组成,主要工作是观察“大数据”、“物联网”或AI等技术领域的趋势和发展。
[7] International Working Group on Data Protection in Technology (Berlin Group). Working Paper on Large Language Models (LLMs) .2024.12. 27,详见https://www.bfdi.bund.de/SharedDocs/Downloads/EN/Berlin-Group/20241206-WP-LLMs.pdf?__blob=publicationFile&v=2
[8] 参见 Rishi Bommasani, Drew A. Hudson, Ehsan Adeli et al., “On the Opportunities and Risks of Foundation Models,” August 2021, https://doi.org/10.48550/arXiv.2108.07258.
[9] 参见 Amanda Askell, Yuntao Bai, Anna Chen et al., “A General Language Assistant as a Laboratory for Alignment,”2021, https://doi.org/10.48550/arXiv.2112.00861.
[10] 提示是提供给大语言模型(LLM)的一组指令。它可以定制或增强大语言模型的能力,形式可以是问题、陈述或信息请求。 大语言模型会分析提示并实时生成响应,例如提供信息、进行总结、回答问题或生成内容。参见Jules White, Quchen Fu, Sam Hays et al., “A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT,” February 2023, http://arxiv.org/abs/2302.11382
[11] 温度是一个配置变量,用于调整大语言模型(LLM)生成回复的随机程度。参见Prompt Engineering Guide, “LLM settings,” https://www.promptingguide.ai/introduction/settings.
[12] 参见Apostol Vassilev, et al., Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations, NIST AI 100-2e2023 (Jan. 2014), https://doi.org/10.6028/NIST.AI.100-2e2023
[13] 见注释2。
[14] https://gdpr-info.eu/art-4-gdpr/
[15] 见注释2。
[16] https://gdpr-info.eu/art-25-gdpr/
[17] 见注释4。
[18] 详见Rigaki/Garcia, A Survey of Privacy Attacks in Machine Learning, 2020, https://dl.acm.org/doi/pdf/10.1145/3624010
[19] 详见Kaulartz/Braegelmann, Rechtshandbuch Artificial Intelligence und Machine Learning, 2020, p.467 para.13.

